北航等机构发布最新综述:大语言模型集成 | ArXiv 2025
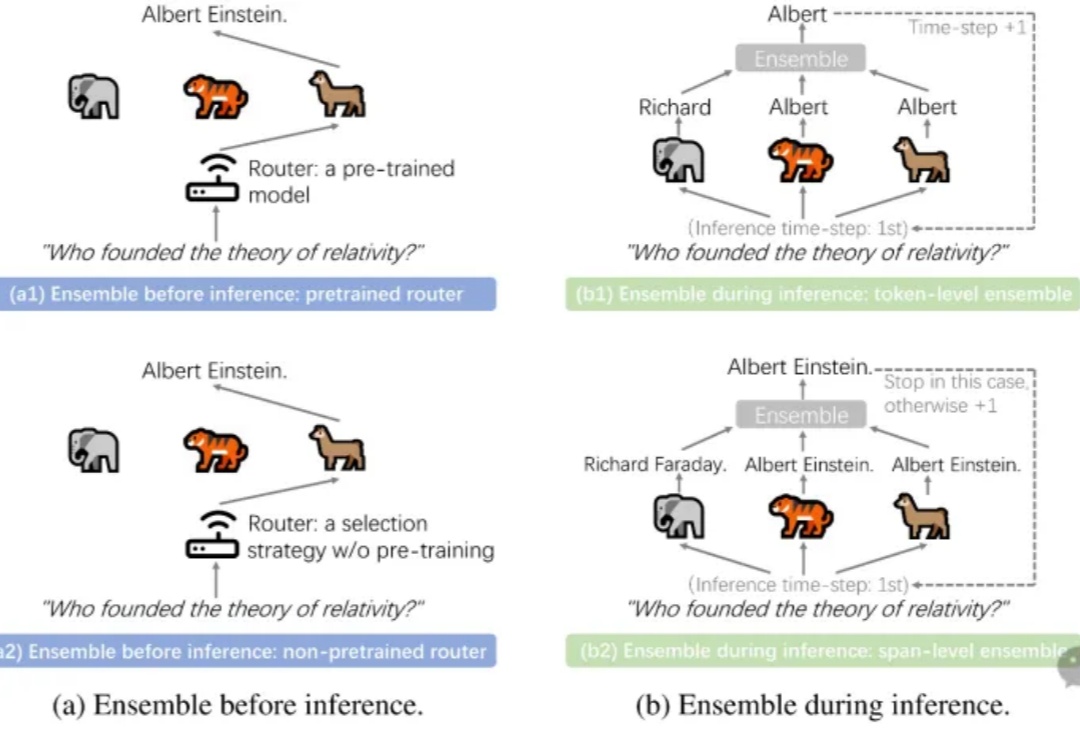
北航等机构发布最新综述:大语言模型集成 | ArXiv 2025LLM Ensemble(大语言模型集成)在近年来快速地获得了广泛关注。它指的是在下游任务推理阶段,综合考虑并利用多个大语言模型(每个模型都旨在处理用户查询),从而发挥它们各自的优势。大语言模型的广泛可得性,以及其开箱即用的特性和各个模型所具备的不同优势,极大地推动了 LLM Ensemble 领域的发展。
来自主题: AI技术研报
9981 点击 2025-06-17 17:03